파일 시스템(file system) 파일과 디렉터리를 관리하는 운영체제 내의 프로그램. 파일과 디렉터리를 다루어 주는 프로그램.
파일과 디렉터리
: 보조기억장치의 데이터 덩어리.
파일
디렉터리
- 보조기억 장치에 저장된 관련 정보의 집합. - 의미 있고 관련 있는 정보를 모은 논리적 단위. >>관련있는 정보를 한데 모아놓은 단위 == 파일.
- 윈도우에서는 폴더(folder) - 옛날엔 : 1단계 디렉터리 - 요즘엔 : 여러계층으로 파일 및 폴더를 관리하는 트리 구조 디렉터리(가장 최상단에 있는 디렉터리를 루트 디렉터리라 부름(/ 슬래쉬로 표현) )
파일을 이루는 정보
디렉터리 경로
파일을 실행하기 위한 정보 + 부가 정보( = 속성, 메타 데이터)
디렉터리를 이용해 파일/ 디렉터리의 위치, 나아가 이름까지 특정 지을 수 있는 정보. 절대 경로와 상대 경로. 같은 디렉터리에는 동일한 이름의 파일이 존재할 수 없지만, 서로 다른 디렉터리에는 동일한 이름의 파일이 존재할 수 있음.
파일의 속성 정보
경로의 종류
속성 이름
의미
절대 경로 : 루트 디렉터리에서 자기 자신까지 이르는 고유한 경로(e.g.> /home/nomatter-me/a.cpp) >> 루트 디렉터리 부터 시작하는 경로.
유형
운영체제가 인지하는 파일의 종류. 확장자로서 특정 지을 수 있음.(cpp,xml등)
상대 경로: 현재 디렉터리에서 자기 자신까지 이르는 경로 (e.g> 현재 디렉터리 경로가 /home일 경우 guest/d.jpg) >> 현재 디렉터리부터 시작하는 경로.
크기
파일의 현재 크기와 허용 가능한 최대 크기.
디렉터리 연산을 위한 시스템 호출
보호
어떤 사용자가 해당 파일을 읽고, 쓰고, 실행할 수 있는 지를 나타냄.
1. 디렉터리 생성 2. 디렉터리 삭제 3. 디렉터리 열기 4. 디렉터리 닫기 5. 디렉터리 읽기 등
생성 날짜
파일이 생성된 날짜.
사실, 많은 운영체제에서는 디렉터리를 그저 "특별한 형태의 파일"로 간주한다! 즉, 디렉터리는 그저 "포함된 정보가 조금 특별한 파일". -------------------------------------------------------------------------------- 파일의 내부에는 파일과 관련된 정보들이 있다면, 디렉터리의 내부에는 해당 디렉터리에 담겨있는 대상과 관련된 정보들이 담겨있다. >> 이 정보는 보통 테이블(표) 형태로 구성.
마지막 접근 날짜
파일에 마지막으로 접근한 날짜.
마지막 수정 날짜
파일이 마지막으로 수정된 날짜.
생성자
파일을 생성한 사용자.
소유자
파일을 소유한 사용자.
위치
파일의 보조기억장치상의 현재 위치.
파일 연산을 위한 시스템 호출
디렉터리 엔트리
1. 파일 생성 2. 파일 삭제 3. 파일 열기 4. 파일 닫기 5. 파일 읽기 6. 파일 쓰기 등
각 엔트리(행)에 담기는 정보 - 디렉터리에 포함된 대상의 이름, 그 대상이 보조기억장치 내에 저장된 위치(를 유추할 수 있는 정보), 가끔 파일 속성을 명시하는 경우도 있음.
파일 시스템이 파일과 디렉터리를 보조기억장치에 할당하고 접근하는 방법과 대표적인 파일 시스템의 종류(FAT 파일시스템, 유닉스 파일시스템) 대해 공부해 보자.
파티셔닝과 포매팅
- 파티셔닝과 포매팅을 해야지 파일시스템을 통해 파일과 디렉터리에 접근 가능
파티셔닝
포매팅
- 저장 장치의 논리적인 영역을 구획하는 작업. 이 떄 구획된 각각의 구역을 파티션이라 함.
- 파일 시스템을 설정. (파일 시스템은 포매팅할 때 결정 됨.) - 어떤 방식으로 파일을 관리할 지 결정, 새로운 데이터를 쓸 준비를 하는 작업
- 파일 시스템에는 여러 종류가 있고, 파티션마다 다른 파일 시스템을 설정할 수도 있다. 포매팅까지 완료하여 파일 시스템을 설정했다면 이제 파일과 디렉터리 생성이 가능해진다.
< 파일 할당 방법 > - 포매팅까지 끝난 하드 디스크에 파일을 저장하기. - 운영체제는 파일/ 디렉터리를 블록 단위로 읽고 쓴다. >> 즉, 하나의 파일이 보조기억장치에 저장될 때에는 여러 블록에 걸쳐 저장된다. (하드 디스크의 가장 작은 저장 단위는 섹터이지만 보통 블록 단위로 읽고 쓴다.)
- 파일을 보조기억장치에 할당하는 두 가지 방법 : 연속 할당, 불연속 할당(오늘날 사용되는 방식)
연속 할당
불연속 할당
: 이름 그대로 보조기억장치 내 연속적인 블록에 파일 할당. > 파일이 저장 장치 내에서 연속적인 공간을 차지하도록 블록을 할당하는 방법.
연결 할당 : 각 블록의 일부에 다음 블록의 주소를 저장하여 각 블록이 다음 블록을 가리키는 형태로 할당.(더이상 불러들일 주소가 없을 경우 다음 블록의 주소에 -1 삽입) >>파일을 이루는 데이터 블록을 연결 리스트로 관리. >>불연속 할당의 일종 : 파일이 여러 블록에 흩어져 저장되어도 무방.
디렉터리 엔트리 : 파일 이름 & 첫번째 블록 주소 & 블록 단위의 길이
색인 할당 : 파일의 모든 블록 주소를 색인 블록이라는 하나의 블록에 모아 관리하는 방식. >> 파일내 임의의 위치에 접근하기 용이
디렉터리 엔트리 : 파일 이름 & 색인 블록 주소
연속된 파일에 접근하기 위해 파일의 첫 번째 블록 주소와 블록 단위의 길이만 알면 된다.
디렉터리 엔트리 : 파일 이름 & 첫 번째 블록 주소 & 블록 단위 길이 명시.
연속 할당의 부작용
연결 할당의 단점
: 구현이 단순하지만 외부 단편화를 야기할 수 있다. ex> 연속할당을 해둔 파일 중 중간 파일들을 삭제했을때 삭제한 파일의 블록수보다 더 큰 파일을 할당 할수 없음. 파일 A의 블록 개수 4개. 파일 B의 블록 개수 5개. 파일 C의 블록 개수 2개. 파일 D의 블록 개수 6개. 파일 E의 블록 개수 3개. 파일 B와 D를 삭제하면 잔여 블록의 개수는 삭제한 파일들의 블록의 개수 11개(5개 + 6개)가 되는데 추가로 넣을 파일 F의 블록 개수가 10개라 하더라도 빈 블록 위치가 다르기때문에 파일을 할당시키지 못함.
1. 반드시 첫번째 블록부터 하나씩 읽어 들여야 한다. == 파일에 임의의 위치에 접근하는 속도가 느림. 2. 오류 발생 시 해당 블록 이후 블록은 접근이 어렵다.
FAT 파일 시스템 : 연결 할당 기반 파일 시스템, 연결 할당의 단점을 보완 오늘날 많이 사용하는 파일 시스템
- 각 블록에 포함된 다음 블록 주소를 한데 모아 테이블(FAT; File Allocation Table)로 관리
>> FAT가 메모리에 캐시 될 경우 느린 임의 접근 속도 개선 가능
디렉터리 엔트리
파일 이름 & 확장자 & 속성 & 예약 영역 & 생성 시간 & 마지막 접근 시간 & 마지막 수정 시간 & 시작 블록 & 파일 크기
유닉스 파일 시스템 : 색인 할당 기반 파일 시스템. 색인 블록 == i-node (파일 속성 정보와 15개의 블록 주소 저장 가능)
- 사실상 i-node가 파일 시스템의 핵심
디렉터리 앤트리
i-node 번호 & 파일 이름
15개 이상의 블록 주소가 있다면? 유닉스 파일 시스템이 큰 파일들을 어떻게 관리하는지 확인해 보자. 1. 블록 주소 중 12개에는 직접 블록 주소 저장. (직접블록 : 파일 데이터가 저장된 블록) 2. 1번으로 충분하지 않다면 13번째 주소에 단일 간접 블록 주소 저장. (단일 간접 블록 : 파일 데이터를 저장한 블록 주소가 저장된 블록) 3. 2번으로 충분하지 않다면 14번째 주소에 이중 간접 블록 주소 저장. (이중 간접 블록 : 단일 간접 블록들의 주소를 저장하는 블록) 4. 3번으로 충분하지 않다면 15번째 주소에 삼중 간접 블록 주소 저장. (삼중 간접 블록 : 이중 간접 블록들의 주소를 저장하는 블록) >> 이렇게 하면 못 담을 데이터가 없음
만약 태어날 때부터 내 눈이 언제까지 사용 가능한지가 정해져 있게 태어난다면 어떻게 될까?
갑작스러운 사고라도 나지 않는 경우 외에 내가 볼 수 있는 시간의 유효기간. 태어난 시간부터의 기준으로 죽을 때까지 눈을 뜨고 있는 시간이 제한되는 그런 생각!
우선 태어났을 때 부터 생각을 해보자.
나의 아이가 과연 얼마나 세상을 보고 살아갈 수 있을지에 대해 아마도 손가락, 발가락 개수보다 먼저 확인하는 상황이 올 것 같다. 타인에 비해 기간이 짧을 수도, 길 수도 있는 눈의 유효기간이기에 병원에선 이 시간에 따라 축하의 말도, 유감의 말도 전할 것이다.
그리고 그 기간이 길든 적든, 부모의 얼굴을 아주 잠깐 보여주고, 아이의 눈을 곧장 검은 천으로 가리고 신생아실로 옮겨둘 것이다. 아기의 입장에선 지금은 굳이 세상을 바라볼 필요가 없는 시간일 테니.
여기서 추가로 생각할 수 있는 관점은 두 가지가 있다. 지금처럼 안구 이식이 안 되는 세상과, 현대의학이 발달해서 안구 이식이 가능한 세상.
전자의 안구 이식이 가능하지 않은 세상을 산다면, 세상사람들은 모두가 이미 눈을 감고 생활하는 습관이 들어져 있을 것이다. 눈이 필요한 직업들은 다른 직업에 비해 연봉이 하늘을 치솟는다. 세상에 태어날 때 유독 눈의 수명이 길었던 사람들이 이 자리를 꽤 차고 있다. 돈에 대한 욕심 때문에 평범한 눈의 수명을 가진 사람들도 제법 이 일을 하고 있는 경우도 있다. 다른 직업에 비해 눈의 수명이 끝났을 경우 보상해 주는 케어 서비스도 잘 돼있기에 일하는 사람이 부족하진 않다.
계획적인 사람들은 자신이 오늘 하루동안 어느 정도의 시간 동안 세상을 볼 수 있는지 워치로 알림을 작동시켜 둔다. 일정한 시간 이상 사용이 되면 경고음 또한 들려 나온다. 사람들은 자신의 가족들에서 전해져 오는 경험과, 주변의 환경에 따른 자신만의 관심의 기여에 따라 무엇을 볼지 무엇을 포기할지를 결정한다. 안타깝게도 태어날 때부터 버려지거나, 어렸을 때 부모의 손에서 크지 못하는 아이들에겐 이러한 지식이 부족하다. 아무래도 보육원이나 관리 센터에선 부모의 사랑보단 더 관대한 제한을 둘 테니 말이다.
눈의 수명은 돈이 많은 부자에게도, 돈이 없는 거지에게도 공평하게 더 이상 늘어나지 않는다. 하지만 세상은 다르게 살 것이다. 부자들은 과정에서 필요한 확인은 타인의 눈의 수명을 사서 해결하고, 오로지 결과에서만 자신의 눈으로 확인한다. 아무래도 돈이 있기 때문에 남들보다 더 눈의 수명을 절약할 수 있다.
눈의 수명이 유전적인 이유일 수도 있기에, 결혼하기 전에 자신들의 유효기간이 어느 정도였는지 필수로 물어본다. 이미 그들은 연애를 시작할 때부터 이 부분에 대해 알고 시작한 경우도 있다. 누가 봐도 낮은 유효기간인 사람들은 어쩌면 그들끼리의 세상을 살 수도 있다. 오히려 남들보다 더 많이 내적 된 경험치를 통해 행복하게 살수도 있다. 오디오 북을 출판하여 떼돈을 벌 수도 있다랄까. 아, 이 세상엔 더 이상 책을 눈으로 읽는 사람들은 거의 없어졌다. 허세로도 보일지 모르는 행동이기에 오디오 북으로 만들어져있지 않은 책들로만 어쩌다 가끔 볼 수 있다.
사람들은 사랑하는 사람들을 보기 위해, 맛있는 음식을 기억하기 위해, 여행 간 공간에서의 추억을 위해, 학교의 입학식이나 졸업식같이 새로운 시작을 위해, 마지막의 끝맺음을 위해, 계절의 변화를 확인하기 위해... 등등. 다양한 이유로 자신에게 남은 눈의 유효기간을 사용한다. 예전 시대에는 사람들이 자기 전에 핸드폰을 하면서 시간을 보내기도 했다는데 이제는 사치 중에 사치적인 행동일 뿐이다.
예전과 달라진 점이 있다면 사진을 많이 찍어 둔다는 것. 몇몇의 사람들은 눈의 유효기간이 거의 남지 않았을 때 그동안 찍어뒀던 사진을 본다. 앞으로 더 이상 못 볼 자신을 위해 자신이 가장 좋아했던 순간을 마지막으로 바라보는 시간을 갖는 것이다. 또 몇몇은 이제 곧 수명이 끝나가는 입장에서 아직 눈의 수명이 남아있을 때 그동안 찍어 뒀던 사진을 본다. 그리웠을 추억들이나, 좋았던 기억이 담긴 사진들을 보며 자신의 마지막 남은 시간들을 정리한다. 물론 동영상 또한 남겨두는 사람들이 있지만 제대로 찍혀 있는 것은 드물다. 처음과 끝만 확인하였기에 중간에 카메라가 움직였다면 그 상태로 찍혀있기 때문이다. 시간도 여유롭지 않다.
아, 범죄를 저지른 범죄자들에겐 형벌이 더 가혹해졌다. 형이 정해지면 하루 9시간의 시간은 반드시 눈을 뜨고 있어야 하기 때문이다. 그렇기에 자칫 유효기간이 적은 사람이라면 교도소에서 유효기간을 다 쓰고 나오는 경우도 존재했다. 아무래도 세상이 변하다 보니 범죄에 대한 불안감이 커진 사람들이 시위를 통해 주장했던 내용인데, 범죄자들의 인권을 참작해 교도소 내부에서 하루 9시간의 사회봉사를 하는 것으로 타협을 보았다. 이 시위를 통해 재정된 법은 세상에 이득이 되긴 했다. 예비 범죄자들에게 범죄를 저지르기 전에 최소한 한 번의 브레이크가 존재하게 된 것이다. 교도소 내에서 9시간의 사회봉사를 한다 해서 형벌에서 차감되는 방식도 아니라 범죄율은 감소했고, 재범률 또한 더 낮아졌다. 나쁘지 않은 결과다.
후자인 안구 이식이 가능한 경우를 생각해 보자. 굉장히 부정적인 생각들로만 가득 차오르는 상황이다.
평범한 사람들은 아마도 역시나 이미 눈을 감고 사는 세상에 익숙해져 있을 것이다. 하지만 부자들과 범죄자들은 다르다.
한 생명이 탄생하는 소중한 순간, 부모들은 아이의 눈의 유효기간을 의사보다, 간호사보다 빠르게 확인하고자 원할 것이다. "부디 적지도 많지도 않은 평범한 기간이여라."라고 기도하면서 말이다.
아이의 눈의 유효기간이 긴 경우, 수많은 곳에서 부모의 핸드폰으로 누가 먼저라 할 것 없이 전화가 온다. 사람들은 당장 그 눈을 사고 싶다는 말들 뿐, 아이의 건강엔 관심이 없다. 아이의 눈 수명은 누구나 노릴 수밖에 없는 빨간 문신 같은 것이다. 그도 그럴 것이 이미 병원들은 태어난 모든 아이들의 눈 유효기간을 태어나자마자 스폰받고 있는 비밀리스트에 업데이트시켜 둔다. 국가는 이러한 문제들 속에서 산모가 충분한 회복을 할 수 있도록 1년 정도의 안전 가옥을 제공한다. 하지만 1년이란 시간은 생각보다 길지 않다. 그럼에도 그나마 괜찮은 건 아이의 눈이 아직 작기에 완벽한 타깃이 되지는 않는다.
사람의 안구도 크기가 맞아야 이식을 해도 이질감이 없기에 보통은 연령대가 비슷한 사람의 안구를 많이 선호한다. 이런 경우 때문에 현재 가장 문제가 되고 있는 범죄가 바로 납치와 유괴이다. 거의 대부분의 사람들은 안타깝게도 태어나자마자 눈의 수명도 아껴야 하는 이 시기에 범죄에서도 안전하지 않다. 성인의 경우는 납치나 유괴 이후 안구만 적출되고 살아서 돌아오는 경우가 있지만, 아이들의 경우는 실종으로 넘어간다. 보통 더 이상 사람의 손을 타지 않을 정도로 성장한 아이들이 이 경우에 해당하는데 눈을 가리고 필요한 연령대가 될 때까지 키워졌다가 안구 적출 후 버려지는 경우가 대부분이다.
국가에서 운영되는 안구센터도 있다. 갑작스러운 사고나, 죽기 전 아직 수명이 남은 눈들을 저장, 혹은 기증받아 따로 관리하는 센터이다. 보통은 가족들에게 이식이 되는 경우도 많지만 자신들의 눈에 아직 유효기간이 남아있을 때, 안구관리 비용을 내고 최대 5년까지 안구센터에 안구를 저장해 둘 수 있다. 기증되어 있는 안구일 경우는 대기를 통해 이식을 받을 수 있다. 물론 비용도 들지만, 기증된 안구의 수에 비해 대기 번호가 워낙 길어서 대기자로 걸어둔 상태였다가 사망했을 경우 자식에 한해서 대신 받을 수 있는 기회를 준다.
이렇게 부정적인 생각들만 한 가득이지만, 오히려 긍정적인 생각도 할 수 있는 시대다.
안구이식이 가능하다는 의학의 발전은 동물의 눈에서도 유전자 변형을 통해 안구를 만들어 내거나 이식시킬 수 있는 세상이 되었을 수도 있다는 말이다. 오히려 외형적으로 안구를 선택해서 교체하는 상황도 올 수 있다.
"오드아이가 되고 싶다면 역시 여기! 500가지가 넘는 색상을 보유하고 있습니다."라는 광고와 함께 안구쇼핑센터가 세워졌다. 더 이상 이 세상엔 시각장애인이 존재하지 않는다. 의학기술이 발달함에 따라 안구의 비용은 누구나 쉽게 살 수 있는 금액대로 떨여졌으며, 그마저도 과열화 되어있다. 이미 안구이식 수술 또한 단순화되어 센터에서 구매한 안구를 그 자리에서 교체가 가능하며, 내년부턴 개인이 직접 교체 가능하게 될 것이라는 찌라시도 돌고 있다. 이제는 안구를 들고 다니면서 시력에 따라 빛에 따라 바꿔 끼울 수 있는 상황이 온 것이다. 더 이상 안경과 선글라스, 렌즈들은 사용되지 않는다. 아주 극 소수의 어떤 이들은 아직도 안경을 사용하기도 하는데 단순히 클래식한 분위기를 좋아하거나, 안경을 쓴 자신의 얼굴이 마음에 들었을 뿐이다.
생각보다 재밌는 상상의 시간이었다. 상황에 따라 더 생각해 보면 끝도 없을 것 같아서 중간중간 그만 멈췄던 것 같다.
마지막에 생각해 본 긍정적인 미래에서 가장 마음에 드는 부분은 "더 이상 이 세상인 시각장애인이 존재하지 않는다."인 것 같다. 세상 모든 사람들이 즐겁고 행복한 세상을 살아가길 바라며 오늘의 상상은 여기까지 해본다.
- 이론적인 fork()시스템 호출 : >> 프로세스는 기본적으로 자원을 공유하지 않는다. >> 부모 프로세스가 적재된 별도의 공간이 자식 프로세스가 통째로 복제(부모 프로세스 복사본)되어 적재. >> 단점: 프로세스 생성 시간 지연, 메모리 낭비(동일한 내용이 메모리에 중복해서 적재되기 때문)
이를 해결하는 방법이 쓰기시 복사 방법. - 쓰기시 복사: >> 부모 프로세스와 동일한 자식 프로세스가 복제되어 생성되면 자식 프로세스는 부모 프로세스와 동일한 프레임을 가리킴(쓰기 작업없다면 이 상태 유지). >> 프로세스는 기본적으로 자원을 공유하지 않는다. 라고 말했듯이 부모 프로세스 / 자식 프로세스 둘 중 하나가 페이지에 쓰기 작업 수행 시 해당 페이지는 별도의 공간으로 복제됨. >> 장점 : 프로세스 생성 시간 절약, 메모리 절약(중복해서 메모리를 저장하지 않기 때문.)
프로세스 테이블의 크기는 생각보다 작지 않다. 프로세스를 이루는 모든 페이지 테이블 엔트리를 메모리에 두는 것은 큰 낭비. 프로세스를 이루는 모든 페이지 테이블 엔트리를 항상 메모리에 유지하지 않을 방법이 바로 계층적 페이징
계층적 페이징 (== 다단계 페이지 테이블)
- 페이지 테이블을 페이징하여 여러 단계의 페이지를 두는 방식. 페이지 테이블을 여러 페이지로 쪼개고 이 페이지를 가리키는 페이지 테이블(Outer페이지 테이블)을 두는 방식.
- 모든 페이지 테이블을 항상 메모리에 있을 필요가 없어짐.
>> CPU와 가장 가까이 위치한 페이지 테이블(Outer 페이지 테이블)은 항상 메모리에 유지, 필요한 페이지들만 메모리에 유지하면 됨.
- 계층적 페이징을 이용하는 환경에서의 논리 주소
논리 주소의 구조
바깥 페이지 번호
안쪽 페이지 번호
변위
1. 바깥 페이지 번호를 통해 페이지 테이블의 페이지를 찾기. 2. 페이지 테이블의 페이지를 통해 프레임 번호를 찾고 변위를 더함으로서 물리 주소 얻기.
페이징을 통해 물리 메모리보다 큰 프로세스를 실행할 수 있지만, 그럼에도 물리 메모리의 크기는 한정되어 있다. 운영체제는 기존에 적재된 불필요한 페이지를 선별해 보조기억장치로 내보내고(=페이지 교체 알고리즘으로 해결) 프로세스들에게 적절한 수의 프레임을 할당해야 한다.
요구 페이징
- 처음부터 모든 페이지를 적재하지 않고 필요한 페이지만을 메모리에 적재하는 기법. 요구되는 페이지만 적재하는 기법.
요구페이징이 실행되는 기본적인 양상 1. CPU가 특정 페이지에 접근하는 명령어를 실행한다. 2. 해당 페이지가 현재 메모리에 있을 경우(유효비트가 1일 경우) CPU는 페이지가 적재된 프레임에 접근한다. 3. 해당 페이지가 현재 메모리에 없을 경우(유효비트가 0일 경우) 페이지 폴트가 발생한다. 4. 페이지 폴트 처리 루틴은 해당 페이지를 메모리로 적재하고 유효 비트를 1로 설정한다. 5. 다시 1번을 수행한다.
요구 페이징 시스템이 안정적으로 작동하려면 해결해야 할 2가지 문제. 1. 페이지 교체. 2. 프레임 할당.
>> 요구 페이징 기법으로 페이지들을 적재하다 보면 언젠간 메모리가 가득 차게 됨. 당장 실행에 필요한 페이지를 적재하려면 적재된 페이지를 보조기억장치로 내보내야 하는데, 이때 어떤 페이지를 내보낼지 결정하는 방법(알고리즘)이 바로 페이지 교체 알고리즘.
페이지 교체 알고리즘 >> 여러가지가 있지만 그중 제일 중요하게 생각해야 하는 게 바로 페이지 폴트가 적은페이지 교체 알고리즘!!!
- 페이지 폴트가 발생하면 보조기억 장치에 접근해야 해서 성능이 저하되기 때문이다.
페이지 폴트 횟수는 어떻게 알수 있을까? - 페이지 참조열(page reference string) : CPU가 참조하는 페이지들 중 연속된 페이지를 생략한 페이지열. CPU가 논리 주소를 통해 특정 주소를 요구하는데 메인 메모리에 올라와 있는 주소들은 페이지의 단위로 가져오기 때문에 페이지 번호가 연속되어 나타나게 되면 페이지 결함이 일어나지 않음. 따라서 CPU의 주소 요구에 따라 페이지 결함이 일어나지 않는 부분은 생략하여 표시하는 기법을 페이지 참조열이라 한다.
여러 페이지 교체 알고리즘들 중 세가지
FIFO 페이지 교체 알고리즘
- 가장 단순한 방식. - 메모리에 가장 먼저 올라온 페이지부터 내쫓는 방식. - "오래 머물렀다면 나가." <단점> - 프로그램 실행 초기에 잠깐 실행될 페이지가 있을 순 있겠지만, 프로그램 실행 내내 사용될 페이지가 있을 수 있는데 이런 페이지의 경우엔 먼저 적재되어 있다고 내쫓아선 안됨. <보완책> - 2차 기회(second-change) 페이지 교체 알고리즘(참조비트를 통해 내쫓을지 말지 한번의 기회를 더 줌) * 참조비트 1 : CPU가 한 번 참조한 적이 있는 페이지.>> 내보내지 않고, 적재된 시간을 현재 시간으로 설정,맨끝으로 보냄.(가장 최근에 적재된 페이지로 간주) 즉, 한번더 기회를 줌.(참조비트 0으로 초기화 후 적재 시간을 현재 시간으로 설정.) * 참조비트 0 : CPU가 참조한 적이 없는 페이지. >> 내쫓음.
최적 페이지 교체 알고리즘
- CPU에 의해 참조되는 횟수를 고려. - 메모리에 오래 남아야 할 페이지는 자주 사용될 페이지. - 메모리에 없어도 될 페이지는 오랫동안 사용되지 않을 페이지. - 앞으로의 사용 빈도가 가장 낮은 페이지를 교체하는 알고리즘. - 가장 낮은 페이지 폴트율을 보장하는 페이지 교체 알고리즘. - BUT, 실제 구현이 어렵다. -"앞으로 오랫동안 사용되지 않을 페이지? 어떻게 예측하지??" - 다른 페이지 교체 알고리즘 성능을 평가하기 위한 척도로서 하한선으로 간주.
LRU(Least- Recently-Used) 페이지 교체 알고리즘
- 최적 페이지 교체 알고리즘: 가장 오래 사용되지 않을 페이지 교체 방식. - LRU 페이지 교체 알고리즘: 가장 오래 사용되지 않은 페이지 교체 방식. - "최근에 사용되지 않은 페이지는 앞으로도 사용되지 않지 않을까??"
페이지 폴트가 자주 발생하는 이유는 나쁜 페이지 교체 알고리즘을 사용했거나, 프로세스가 사용할 수 있는 프레임 자체가 적어서!!
스래싱과 프레임 할당
< 스레싱 > - 프로세스가 실행되는 시간보다 페이징에 더 많은 시간을 소요하여 성능(CPU이용률)이 저하되는 문제를 말함. - 동시 실행되는 프로세스의 수를 늘린다고 CPU 이용률이 높아지는 것은 아님. - 근본적인 이유 : >> 각 프로세스가 필요로 하는 최소한의 프레임 수가 보장되지 않았기 때문. >> 각 프로세스가 필요로 하는 최소한의 프레임 수를 파악하고, 프로세스들에게 적절한 프레임을 할당해줘야 한다.
< 프로세스의 크기나, 물리 메모리의 크기를 통한 프레임 할당 방식 2가지 > 1. 균등 할당(equal allocation): 가장 단순한 할당 방식. 모든 프로세스들에게 균등하게 프레임을 할당하는 방식. >> 권장은 ㄴㄴ. 상대적으로 크기가 큰 프로그램(게임)과 작은 프로그램(메모장)에게 똑같은 프레임을 할당한다 생각해 봐. 2. 비례 할당(proportional allocation): 프로세스의 크기를 고려. 프로세스 크기에 비례하는 프레임 할당. >> 완벽한 방식은 ㄴㄴ. 크기가 큰 프로세스인데 막상 실행해 보니 많은 프레임을 필요로 하지않거나, 크기가 작은 프로세스인데 막상 실행해보니 많은 프레임이 필요한 경우가 있기 때문. 결국 프로세스가 필요로 하는 프레임 수는 실행해 봐야 안다. ** 균등할당과 비례할당은 프로세스의 실행과정은 고려하지 않고 단순히 프로세스의 크기나, 물리 메모리의 크기만을 고려한 방식이라 정적 할당 방식이라 부름.
< 프로세스를 실행하는 과정에서 프레임을 결정하는 방식 2가지 > 1. 작업 집합 모델 사용 방식 : 프로세스가 실행하는 과정에서 배분할 프레임 결정. 스레싱이 발생하는 이유는 빈번한 페이지 교체 때문이기에 CPU가 특정 시간 동안 주로 참조한 페이지 개수만큼만 프레임을 할당하면 된다. "프로세스가 일정 기간 동안 참조한 페이지 집합"을 기억하여 빈번한 페이지 교체를 방지하는 방식이 작업집합 모델 기반의 프레임 할당 방식. ** 작업 집합이란 "실행 중인 프로세스가 일정 시간 동안 참조한 페이지의 집합". - 작업집합을 구하려면?? > 1. 프로세스가 참조한 페이지 > 2. 시간 간격이 필요함. 2. 페이지 폴트 빈도 기반의 프레임 할당 방식 : 프로세스가 실행하는 과정에서 배분할 프레임 결정. - 두 개의 가정에서 생겨난 아이디어 1. 페이지 폴트율이 너무 높으면 그 프로세스는 너무 적은 프레임을 갖고 있다. 2. 페이지 폴트율이 너무 낮으면 그 프로세스가 너무 많은 프레임을 갖고 있다. 페이지 폴트율에 상한선과 하한선을 정하고, 그 내부 범위 안에서만 프레임을 할당하는 방식. ** 작업 집합 모델 사용방식과 페이지 폴트 빈도 기반의 프레임 할당 방식은 프로세스가 실행하는 과정을 통해서( == 관찰함으로써) 프레임을 할당하는 방식이라 동적할당 방식이라 부름.
using System;
public class Solution {
public int solution(int[] d, int budget) {
int answer = 0;
Array.Sort(d);
int num = d.Length;
for(int i =0; i < num; i++)
{
if (budget >= 0 && (budget - d[i]) >= 0)
{
budget -= d[i];
answer = i+1;
}
else
{
answer = i;
break;
}
}
return answer;
}
}
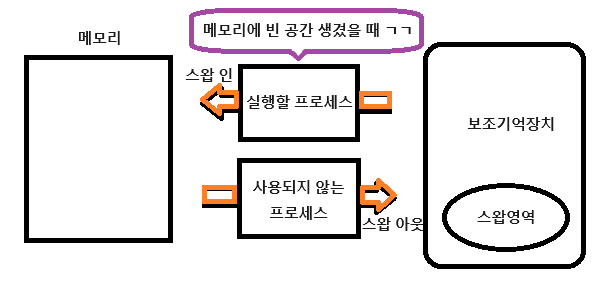
운영체제가 메모리를 관리하는 기본적인 기능 중 하나, 스와핑 : 현재 사용되지 않는 프로세스들을 보조기억장치의 일부 영역으로 쫓아내고 그렇게 생긴 빈 공간에 당장 사용할 새 프로세스 적재
스와핑
- 이점: 프로세스들이 요구하는 메모리 공간 크기 > 실제 메모리 크기 - 스왑영역 크기 확인하기 : free, top명령어로 확인 가능
연속 메모리 할당
- 프로세스는 메모리의 빈 공간에 할당되어야 한다. 빈 공간이 여러개 있다면?
어떤 빈 공간에 할당 될지에 따라 최초 적합, 최적 적합, 최악 적합의 세 가지 방식이 있다.
최초 적합(first-fit)
최적 적합(best-fit)
최악 적합(worst-fit)
- 운영체제가 메모리 내의 빈 공간을 순서대로 검색하다 적재할 수 있는 공간을 발견하면 그 공간에 프로세스를 배치하는 방식. - (빈 공간)검색 최소화, 빠른 할당.
-운영체제가 빈 공간을 모두 검색해본 뒤, 적재 가능한 가장 작은 공간에 할당.
- 운영체제가 빈 공간을 모두 검색해본뒤, 적재 가능한 가장 큰 공간에 할당.
**연속 메모리 할당의 두가지 문제점 사실, 프로세스를 연속적으로 메모리에 할당하는 방식은 메모리를 효율적으로 사용하는 방법이 아님. >> 1. 외부 단편화(external fragmentation)이라는 잠재적 문제가 발생하기 때문. >> 2. 물리 메모리보다 큰 프로세스 실행 불가.
- 외부 단편화란? : 프로세스를 할당하기 어려울 만큼 작은 메모리 공간들로 인해 메모리가 낭비되는 현상. 남아있는 총 메모리 공간이 요청한 메모리 공간보다 크지만, 남아있는 공간이 연속적이지 않아 발생하는 현상. >>해결 방법: 1. 메모리 압축 방식(conpaction) : 여기 저기 흩어져 있는 빈 공간들을 하나로 모으는 방식. 프로세스를 적당히 재배치시켜 흩어져 있는 작은 빈 공간들을 하나의 큰 빈 공간으로 만드는 방법. 2. 가상메모리 관기법 : 실행하고자 하는 프로그램을 일부만 메모리에 적재하여 실제 물리 메모리 크기보다 더 큰 프로세스를 실행할 수 있게 하는 기술. 페이징( 현재 대부분의 운영체제가 사용하는 방법.)과 세그멘테이션이 있음.
외부 단편화가 발생했던 근본적인 문제는 각기 다른 크기의 프로세스가 메모리에 연속적으로 할당되었기 때문.
페이징이란? : 프로세스를 일정 크기로 자르고, 이를 메모리에 불연속적으로 할당함으로써 외부 단편화를 해결.
페이징(paging) : 프로세스의 논리 주소 공간을 페이지(page)라는 일정 단위로 자르고, 메모리의 물리 주소 공간을 프레임(frame)이라는 페이지와 동일한 일정한 단위로 자른 뒤 페이지를 프레임에 할당하는 가상 메모리 관리 기법. - 페이징에서의 스와핑 - 프로세스 단위의 스왑 인, 스왑 아웃이 아닌 페이지 단위의 스왑 인(페이지 인), 스왑 아웃(페이지 아웃) - 메모리에 적재될 필요가 없는 페이지들은 보조기억장치로 스왑 아웃. - 실행에 필요한 페이지들은 메모리로 스왑 인. >> 프로세스를 실행하기 위해 모든 페이지가 적재될 필요 없다. >> 달리 말해 물리 메모리보다 큰 프로세스도 실행될 수 있다.
- 페이지 테이블 : (실제 메모리 내의 주소인) 물리 주소에 불연속적으로 배치되더라도, (CPU가 바라보는 주소인) 논리 주소에는 연속적으로 배치되도록 하는 방법. - 페이지 번호와 프레임 번호를 짝지어 주는 일종의 이정표. - 프로세스마다 페이지 테이블이 있다. - 물리적으로는 분산되어 저장되어 있더라도 CPU 입장에서 바라본 논리 주소는 연속적으로 보임. - CPU는 그저 논리 주소를 순차적으로 실행 하면 될 뿐임. - 외부 단편화를 해결하는 대신 내부 단편화라는 또 다른 부작용이 생김. 그래도 외부 단편화보다 메모리 낭비가 작음.
* 내부 단편화 : 하나의 페이지 크기보다 프로세스 크기가 작은 크기로 발생하는 메모리 낭비 문제. 주기억장치 내 사용자영역이 실행 프로그램보다 커서 프로그램의 사용 공간을 할당 후 사용되지 않고 남게 되는 현상. (100MB의 메모리에 80MB의 크기의 프로세스를 올리게 되면 20MB의 내부 단편화가 발생.)
PTBR (프로세스 테이블 베이스 레지스터) : 각 프로세스의 페이지 테이블이 적재된 주소를 가리킨다. 프로세스마다 페이지 테이블이 있고, 각 페이지 테이블은 CPU내의 프로세스 테이블 베이스 레지스터(PTBR)가 가리킨다.
PTBR
페이지 테이블이 전부다 메모리에 저장되어 있으면 부작용이 발생함. >> 메모리 접근 시간이 두배로 늘어남. (페이지 테이블 참조하기 위해 1번, 페이지 참조하기 위해 1번)
이를 위해 사용하는 방식인 TLB : CPU곁에 페이지 테이블의 캐시 메모리 이용. 페이지 테이블의 일부를 가져와 저장. - CPU가 접근하려는 논리 주소가 TLB에 있다면? : TLB 히트 (메모리 접근 1번) - CPU가 접근하려는 논리 주소가 TLB에 없다면? : TLB 미스 (메모리 접근 2번)
페이징에서의 주소 변환
특정 주소에 접근하고자 한다면 어떤 정보가 필요할까?
- 이떤 페이지/ 프레임에 접근하고 싶은지, 접근하려는 주소가 그 페이지 혹은 프레임으로부터 얼마나 떨어져 있는지에 대해 알아야 됨. (ex> 프로세스 A의 페이지 2에서 10만큼 떨어진 주소에 접근할래!)
페이지 시스템에서의 < 페이지 번호(page number)와 변위(offset) >로 이루어진 논리 주소는
>> 페이지 테이블을 통해 >>
< 프레임 번호, 변위 > 로 이루어진 물리주소로 변환된다.
이 두가지의 변위는 같다.
페이지 테이블 엔트리 (PTE) : 페이지 테이블의 각각의 행 .
현재까지 설명한 PTE: 페이지 번호, 프레임 번호. 이외에 담기는 정보는? 운영체제에 따라 달라지지만 알아보자.
1. 유효 비트 : 현재 해당 페이지에 접근 가능한지 여부. 현재 페이지가 스왑영역으로 쫓겨났는지 아닌지, 현재 페이지가메모리에 적재돼있는지, 아닌지를 나타냄.
- 유효 비트가 0인 페이지에 접근하려고 하면? 페이지 폴트(page fault)라는 인터럽트 발생.
** 페이지 폴트(page fault)라는 인터럽트 1. CPU는 기존의 작업 내역을 백업 2. 페이지 폴트 처리 루틴 실행 3. 페이지 처리 루틴은 원하는 페이지를 메모리로 가져온 뒤 유효 비트를 1로 변경. 4. 페이지 폴트를 처리했다면 이제 CPU는 해당 페이지에 접근할 수 있게 됨.
2. 보호 비트 : 페이지 보호 기능을 위해 존재하는 비트. 보호 비트는 페이지에 접근할 권한을 제한하여 페이지를 보호하는 비트.
3. 참조 비트 : CPU가 이 페이지에 한 번이라도 접근한 적이 있는지 여부.
4. 수정 비트( = dirty bit) : CPU가 이 페이지에 한번이라도 데이터를 쓴 적이 있는지 여부.(수정이 됐으면 1, 안됬으면 0)
수정비트의 존재 이유는? 수정된 페이지는 스왑 아웃될 때 보조기억장치에도 쓰기 작업을 거쳐야(반영해) 하기 때문에.
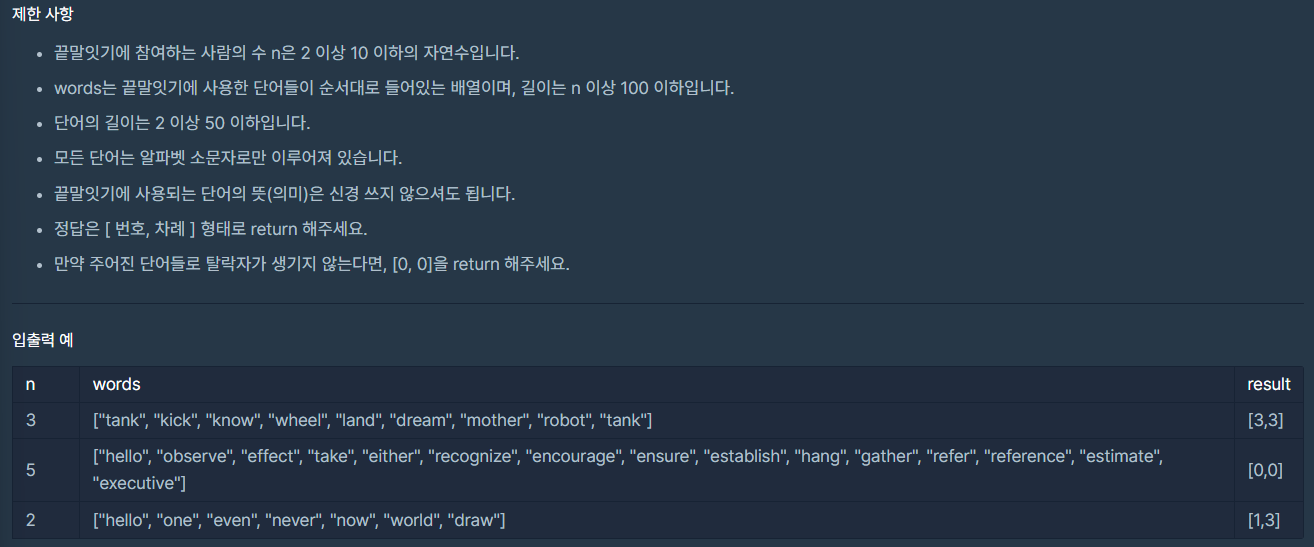
쉬운 문제라 별다른 생각 없이 풀었다가 테스트 10이 틀렸다. 고민하던 찰나에 혹시나 해서 result에 숫자도 없고 x값도 그냥 "x" 일 때인가 싶어서 이 조건 하나 추가 해서 통과했다. 질문창에 가보니 나와 같이 Test10이 문제였던 사람들이 많아서 글로 추가 작성 해뒀었다. 그 후로 내 글 보고 통과됐다는 사람들이 있어서 기분 좋았던 문제.
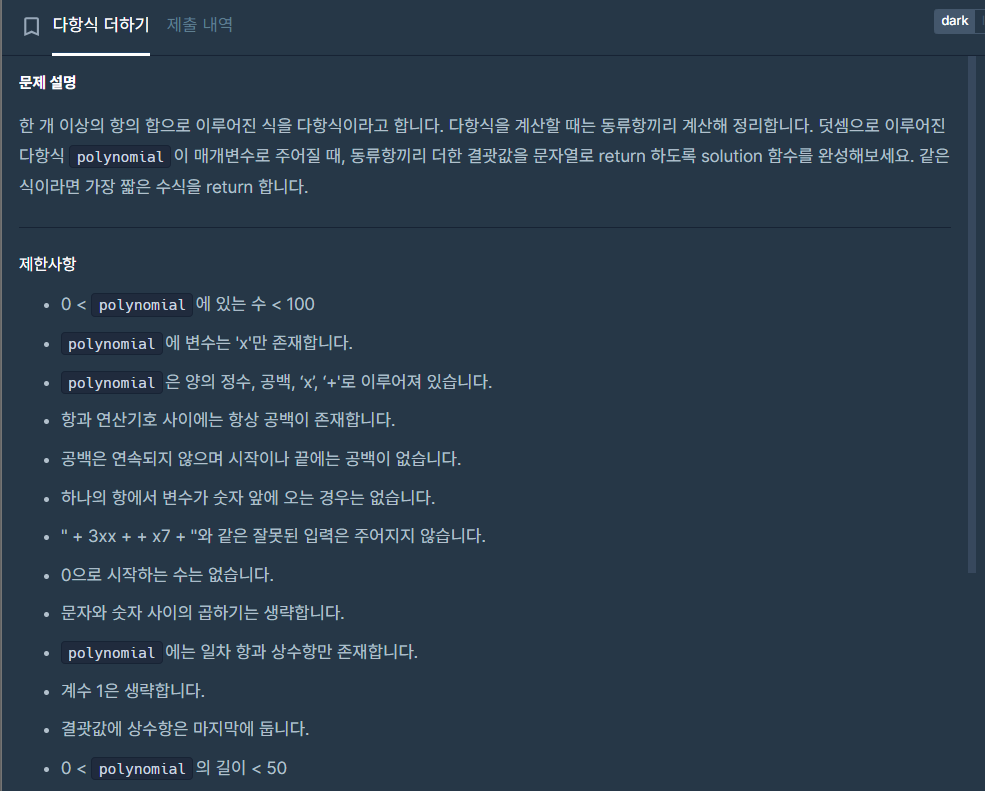
다항식 더하기 문제
내 코드
using System;
using System.Linq;
public class Solution {
public string solution(string polynomial) {
string[] answer = polynomial.Split(" ");
string result = "";
string str = "";
int xNum = 0;
int num = 0;
for (int i = 0; i < answer.Length; i += 2)
{
if (answer[i].Contains("x"))
{
str = answer[i].Replace("x", string.Empty);
if (str == "")
{
str = "1";
}
xNum += Convert.ToInt32(str);
}
else
num += Convert.ToInt32(answer[i]);
}
if (num == 0)
{
if(xNum ==1)
result = "x";
else
result = xNum + "x";
}
else
{
if(xNum ==0)
result = num.ToString();
else if(xNum ==1)
{
result = "x " + "+ " + num;
}
else
result = xNum + "x " + "+ " + num;
}
return result;
}
}