728x90
반응형

인프런에서 만우절을 기념하여 천 원샵을 열었다. 전혀 관심 없던 강의들이지만 천 원이라는 사실에 끌려 커피 한잔 가격만큼만 투자해 볼까라는 생각으로 구매해 보았다.
이벤트로 싸게 얻었으니 이참에 구매한 강의들을 들어보면서 새로운 공부를 배워볼 예정이다.
"웹프론트엔드를 위한 자바스크립트 첫걸음"은 원래 33000원을 내야 하는 강의인데 "한 번에 끝내는 자바스크립트: 바닐라 자바스크립트로 SPA 개발까지"강의를 장바구니에 담을 때 이 강의 역시 천 원에 구매할 수 있도록 쿠폰을 준다 하길래 잽싸게 쿠폰을 받아 같이 구매했다.
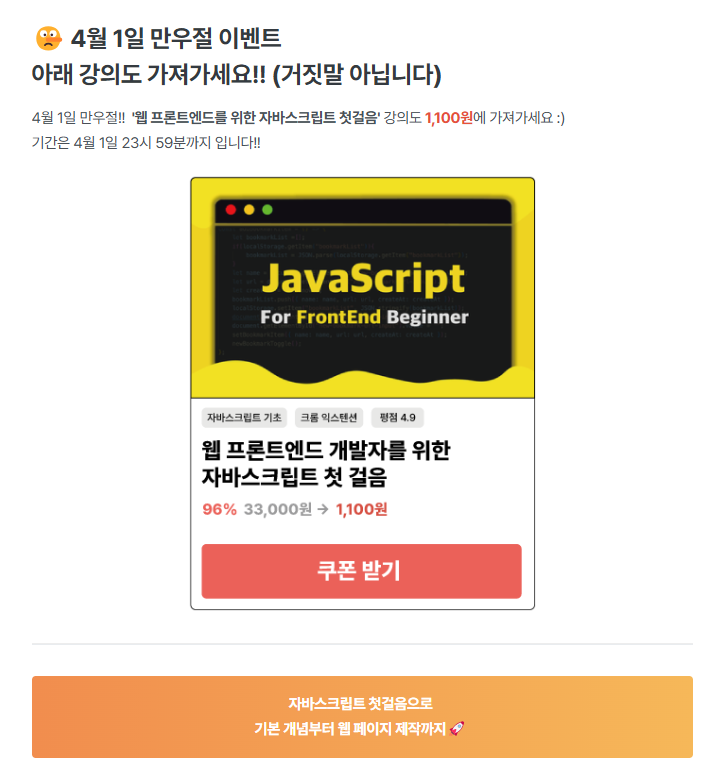
어차피 자바스크립트를 배워본 적이 없기에 "한 번에 끝내는 자바스크립트"강의를 들으려면 기초 언어가 어느 정도 필요할 것 같아 같이 구매하길 잘했다는 생각이 들었다.
그래서 구매하게 된 강의들이 아래에 있는 강의들이다.
5500원을 내고 이런 강의들을 얻게되다니. 인프런이 참 좋아지는 하루다.
내용들도 재밌어보이고 강의들에 하나같이 주옥같은 수강평들이 있길래 기대가 된다. 재밌을 것 같다!
728x90
반응형
'이것저것 > 관심이 닿는 곳' 카테고리의 다른 글
| 머신 러닝 ) 머신 러닝에 대해 알아보자. (1) | 2025.03.17 |
|---|---|
| 젠스파크 ) Genspark의 딥 리서치 기능에 대해 알아보자. (0) | 2025.03.07 |
| Ai 인공 지능 ) 그림생성도, AI 검색도 다 되는 Genspark. (0) | 2025.02.19 |
| 티스토리 ) tistory "붙여넣기 및 이미지 업로드 중입니다" 오류 해결 방법. (0) | 2025.02.19 |
| 유니티 ) 프로젝트 이름을 중간에 바꾸고 싶을 때. (0) | 2024.12.10 |